

5大模块 + 15个实战案例目 + 4个大型企业项目,经历51期同学【反馈 - 优化 - 磨合 - 再优化】,理论与实践科学配比

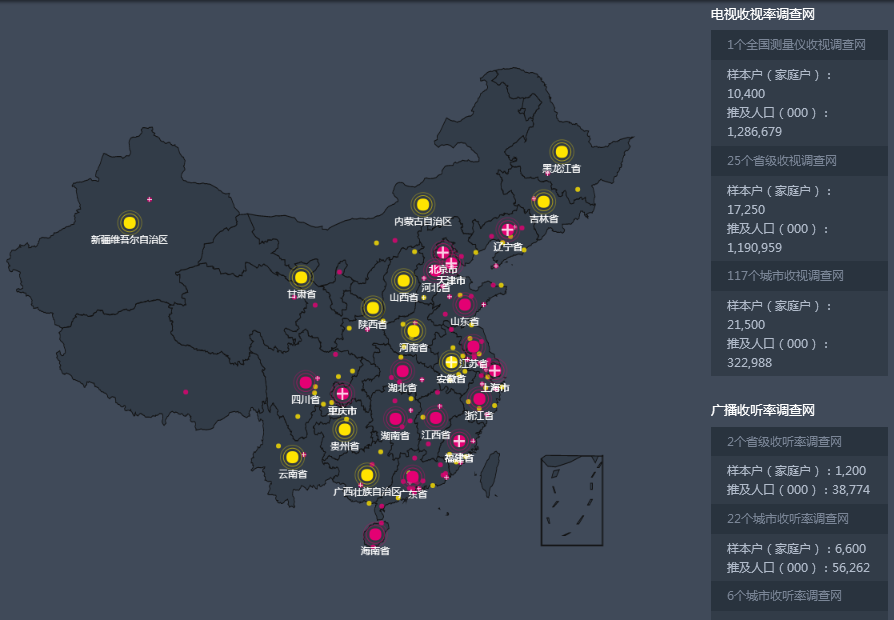
项目1权威机构广电收视率系统(Hadoop)
Zookeeper、Hadoop、Hive、Flume、Sqoop、Azkaban、ECharts
2. 数据量级PB级,全国性业务,样本数据3G+,北京某几个区7天的数据
3. 项目亮点 / 难点a)数据跨小时、跨天企业级解决方案
b)任务调度过程中突然意外中断如何处理?
c)数据倾斜以及故意刷数据如何处理?
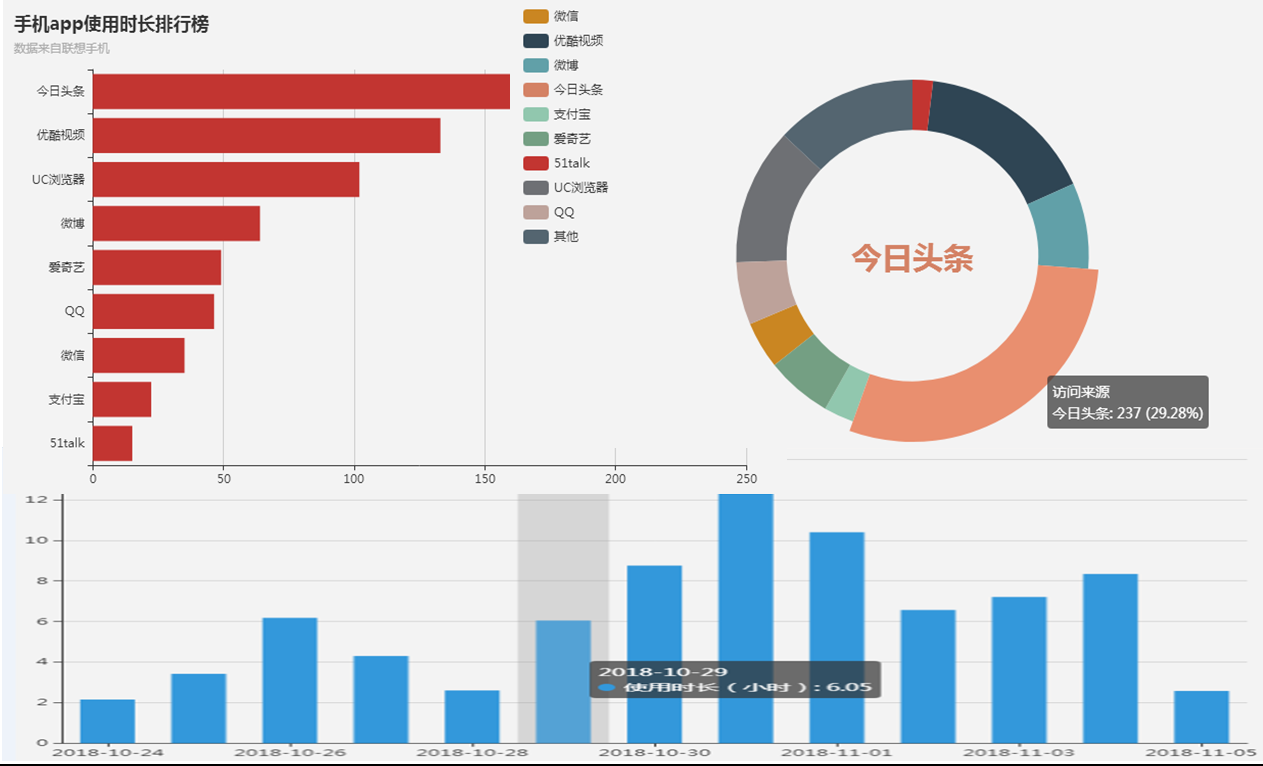
项目2知名手机用户行为实时分析系统(Spark)
Spark、Nginx、Zookeeper、HBase、Flume、Kafka、ECharts
2. 数据量级亿级,每天上亿高并发请求,对性能要求极高
3. 项目亮点 / 难点a)为了减少Spark Streaming reduceBykey聚合数据,如何利用flume+kafka实现预分区优化
b)如何处理SparkStreaming的代码升级后,造成反序列化checkpoint目录中的数据失败问题?
c)如何解决大数据项目中的高吞吐、高并发的实际难题
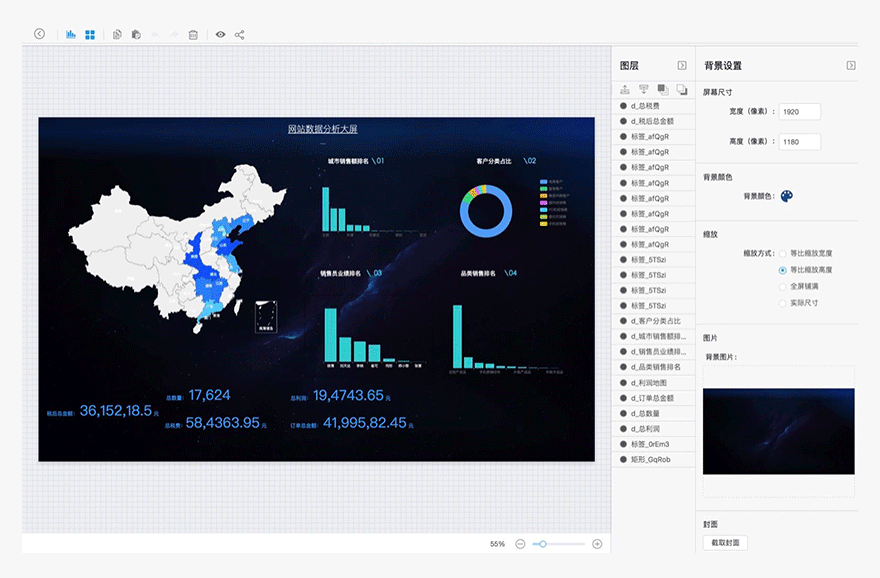
项目3运营商大数据平台监控预警系统(Flink)
Flink、Hadoop、Hive、HBase、Canal、Flume、Kafka、ElasticSearch
2. 数据量级大数据平台各个集群实时产生的数据
3. 项目亮点 / 难点1)权限管理宽松混乱
a)申请:使用者申请权限时,不清楚具体资源细节或为了省事,申请时申报了过多接口机的权限
b)审批:审批时,由于没有时间和精力对权限逐条核对,导致审批失去意义
c)回收:目前权限回收机制依赖权限一年有效期和员工离职,导致无法及时回收人员无关的权限
2)数据资源管理混乱
a)所有人都有建表的权限,导致现在很多表用途不明,归属不明
b)基础数据表直接对外提供使用,没有采用中间层进行隔离
c)由于无法确认某张表被谁引用,所以有新需求要更新表结构时,确认的工作量非常大
d)尽管很多表不再被使用,但用途不明,归属不明,不敢轻意进行清理
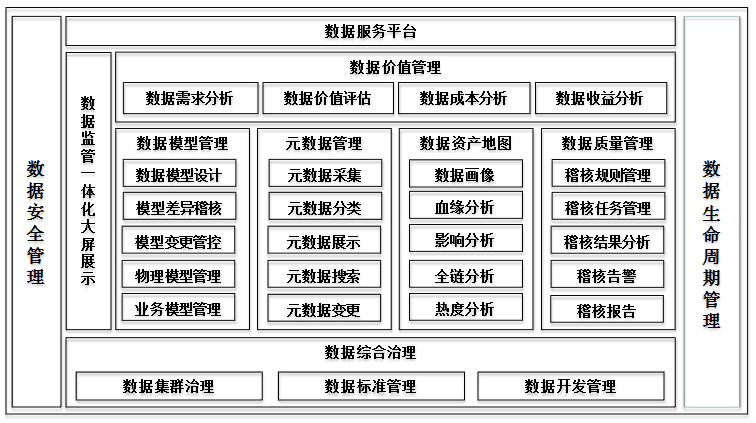
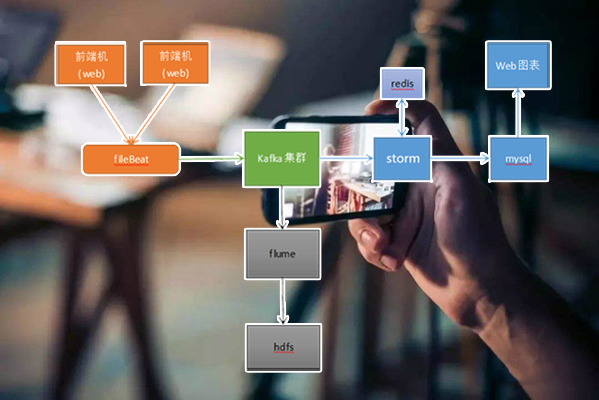
项目4某直播平台互联网金融项目(Storm)
Storm、Hadoop、Redis、Filebeat、Flume、Kafka、MySQL
2. 数据量级直播平台实时产生数据
3. 项目亮点 / 难点a)集群分布式锁的实现
b)数据采集源码二次开发
c)线上项目稳定性及性能优化